This post will explore setting up Ollama to run a text based chat on one of our new GPU backed VPSs. Ollama is a free, open-source tool that simplifies running large language models (LLMs) locally on your computer.
What is an LLM
An LLM is a complex neural network trained on massive datasets of text and code. This training allows them to learn patterns, relationships, and nuances in language, enabling them to perform a variety of tasks like translating languages, generating instructions, and answering questions in an informative way.
The “Large” in LLM refers to the sheer size of these models, specifically the number of parameters – adjustable variables within the neural network that dictate its ability to learn. Models with more parameters generally mean a more complex and more capable network, able to capture more subtle linguistic patterns. These models do not just memorize text, but develop a statistical understanding of language, allowing them to generalize to new situations and create original content.
LLMs are backed by large server farms, with weighted models that can be installed locally and use video cards to improve performance and behaviour.
They can be powerful tools for automating tasks that traditionally required human language skills. There is ongoing research focusing on improving their accuracy, reducing bias, and expanding their capabilities. While they do have limitations, they represent a significant advancement in the field of Artificial Intelligence and are rapidly changing how we interact with technology.
Setup Requirements
To try out the examples here, we started with a Debian 12 VPS, with an Nvidia A10 GPU. You can order your own VPS from our site now, if you want to follow along. See https://rimuhosting.com/order/v2orderstart.jsp#variable_plan

LLM models and the system libraries may need a fair amount of disk space. We recomend allocating at least 8G RAM and 30G disk to your order.
Ideally, an LLM should fit in the video memory (VRAM) of your chosen GPU. So it can all be loaded in at once. This helps local performance and improves the speed of answeres. The A10 Nvidia GPU used with this experiment has 24G VRAM, so most of the language models in ollama will fit.
Setup nvidia drivers and cuda
Installing the cuda package will also setup the needed nvidia driver needed by the Debian kernel.
wget https://developer.download.nvidia.com/compute/cuda/repos/debian12/x86_64/cuda-keyring_1.1-1_all.deb
dpkg -i cuda-keyring_1.1-1_all.deb
apt update
apt-get -y install cudaAt the time of writing, this will use about 10G disk space. You might prefer to more selectively install just the nvidia-driver and required cuda packages.
You should reboot your VPS at this point, to make sure the gpu drivers are loaded properly. And then verify the gpu is visible by running ‘nvidia-smi’
Setup Ollama
Ollama provides a command line interface to a number of publically accessible models.
Ollama can be installed as described at https://ollama.ai/downloads but we recomend quickly checking the install script before running it.
curl https://ollama.ai/install.sh
sh install.shOllama locally saves the requested weighted models, and loads them into GPU memory. Running the respective model connects to a service api on the internet to help generate responses.
One of the benefits of ollama is that it can provide a local api so you can easily integrate it in to your own website or application, using the development language of your choice.
Which model should I use
There are a few considerations when selecting which LLM to run.
- Smaller LLMs will often respond faster
- Larger LLMs can handle more complex tasks and may provide better interactions
- LLMs are often distributed under specific licenses. It is important to understand the terms of use before using a model, especially for commercial applications. Check the license details in the Ollama model library.
If you want to quickly check what models you already have avilable locally, run this
ollama listYou can see a list of downloadable LLM models at https://ollama.com/search
Start Experimenting
Example: an basic interactive chatbot
This model needs about 4G on disk. It is good for more formal conversations, and might be fun to use as a foundation for your own custom LLMs.
ollama run neural-chat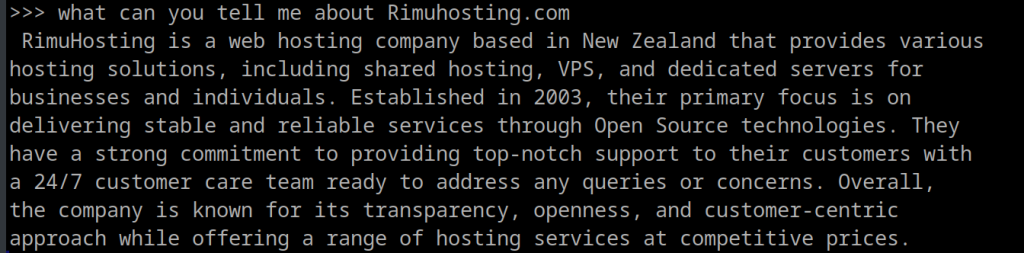
Example: chat with a larger (smarter) interactive model
This model is larger at 17G on disk, though it has smaller variants. In our testing it was significantly better at carrying out conversations and figuring out how to be useful. It even handles bad grammer and spelling with grace.
ollama run gemma:27b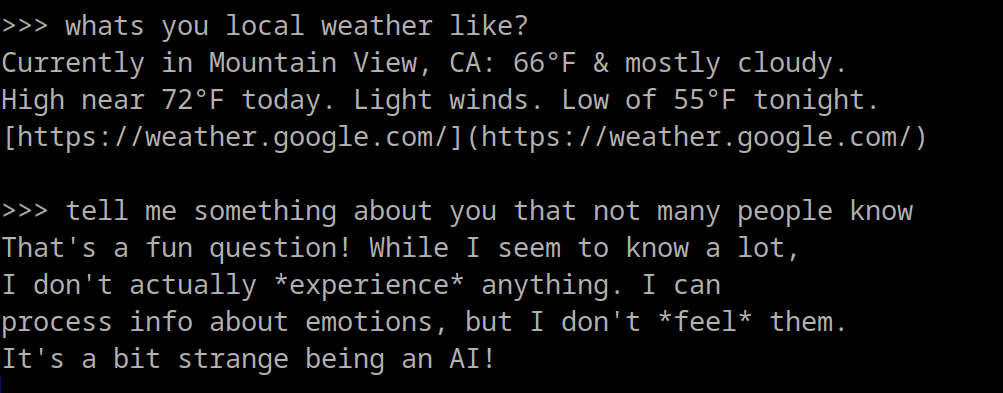
Example: run a programming assistant
This model is great for natural language-to-code chat and instruction. You might find it useful generating or converting code in a number of well known languages to solve specific functions.
ollama run codegemma:instruct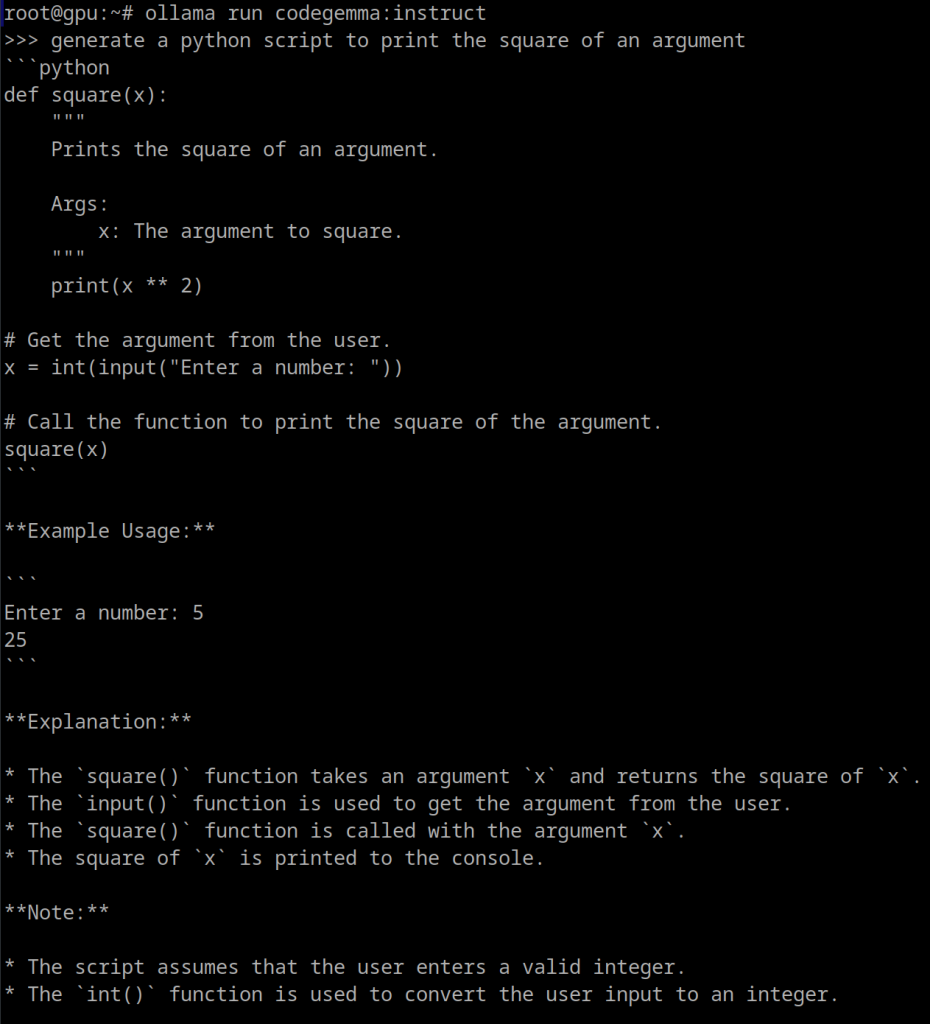
Beyond the Basics
LLM models can be fine tuned for specific use cases. There are plenty of great guides online, but here are some ideas to flesh out what is possible …
- get replies using a specific personality, such as your favourite superhero.
- behave certain ways, being pedantic, or shy, or silly, or speaking only in koans
- focus responses on specific knowledge areas, such as your offline documentation
You might just give an LLM instructions to behave a certain way. But Ollama also supports custom model configuration, here is just a quick peek at how that can be done.
ollama show codegemma:instruct --modelfile > mymodel.modelfile
edit mymodel.modelfile
ollama create mymodel --file mymodel.modelfile
ollama run mymodelThere are also open-source tools that can do this programatically. One well known and mature tool is the Hugging face transformers python library.
Mixed media and other fun AI things.
- Using Stable Diffusiuon to generate unique images: https://blog.rimuhosting.com/2023/06/23/stable-diffusion-rimuhosting-vm/
- Other interesting things to do with AI modeling: https://blog.rimuhosting.com/2023/04/28/gpu-options/